In the ever-evolving landscape of customer service, understanding and acting on customer feedback is important. Recently, we analyzed the reasons why e-commerce customers returned products. Especially when a lot of feedback is received, or when different feedback pops up, machine learning can come to the rescue. Algorithms can help to highlight the most important improvements, or alert about new issues with a latest batch of products. If we want to analyze feedback, we want to detect the underlying reasons by summarizing comments and putting them in buckets or clusters. We applied 2 methodologies.
Methodology 1: embeddings
The primary goal of this project is to understand the main reasons why customers return products. We utilized embeddings to transform the comments into vectors and cluster them using affinity propagation. The embeddings were constructed as two parts. The first part of the embedding was computed based on a preselected return reason, while the second part was computed based on an additional free-form comment. We embedded both separately and then summed them to create a final embedding for each comment.
This approach allowed us to identify distinct groups of complaints, such as issues related to product size, incorrect items received, items delivered in a damaged condition, but also more specific insights like a certain product that did not fit into the fridge as expected. The visualization of these clusters provided a clear view of the predominant reasons for returns.
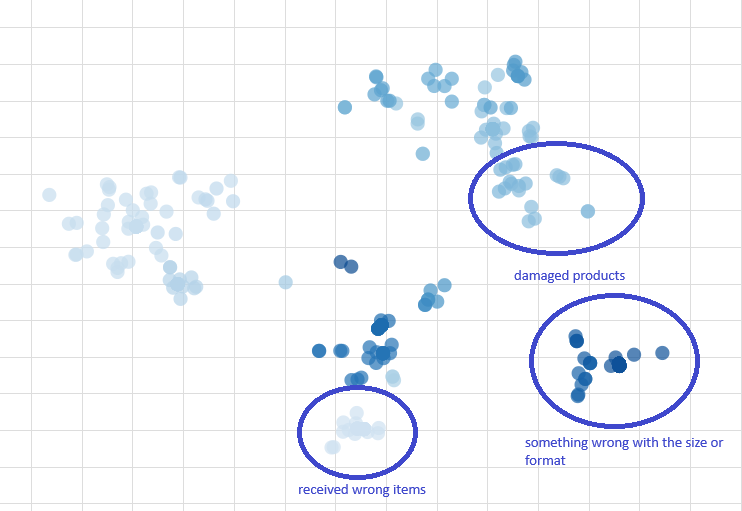
One problem with clustering algorithms is to control the number of clusters that are generated. In this case we saw multiple clusters related to size complaints. Some postprocessing should be done to combine those clusters together (or in other cases split them further).
Another challenge was dealing with the generic preselected return reason “Other”. These caused the embeddings of different return reasons to be biased and clustered together, resulting in mixed clusters. To address this, we could refine our approach by focusing solely on the embeddings from the free-form text.
Methodology 2: leveraging ChatGPT for classification
Instead of working with embeddings, why not simply ask ChatGPT to classify the comments in a predefined set of return reasons? Cost and energy-efficiency arguments aside, ChatGPT performed reasonably well. However, the trick is to associate numbers to the different categories of return reasons and ask the LLM to respond with the numbers instead of the textual descriptions. Otherwise, it might introduce some new categories such as “other” and minor variations like “complaint about the delivery” instead of sticking strictly to the predefined reason “complaint about delivery”. This highlighted both the capabilities and the limitations of using large language models for automated text classification.
Conclusion
To avoid the problem of generating the right number of clusters, we simply asked the LLM to classify the return reasons into a set of predefined and common return reasons. However, clustering still has the potential to discover new types of return reasons which are not included in the predefined set.
Clustering complaints helps brands to improve products and increase customer satisfaction. Our analysis allowed to update product descriptions. One example was to better inform customers about the size of an item, especially if they want to store it in a fridge. Decreasing product returns saves money, the environment and ultimately grows your business. Using data to grow businesses is what we love to do at Searching Pi!
Leave a Reply
You must be logged in to post a comment.